Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- Forums
- :
- Groups
- :
- Location and Language
- :
- Francophones
- :
- Re: Qlik Sense : Comptage avec dimension dynamique
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Feature this Topic
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Qlik Sense : Comptage avec dimension dynamique
Bonjour,
J'ai une table du style
Annee Annee_SCO ID
2017 2017 0
2017 2017 1
2017 2018 2
2017 2017 3
2018 2018 4
2018 5
2018 6
2018 2018 7
/**********************************************************************/
en LOAD j'ai :
SET TypeAnneeSelect = '1';
LOAD ID_FAM as ID_FAM_FH,
ANNEE as ANNEE_FH
ANNEE_SCO as ANNEE_SCO_FH
;
[MA_TABLE]:
SELECT "ID_FAM",
"ANNEE",
"ANNEE_SCO"
FROM MA_TABLE;
/**********************************************************************/
J'ai ajouter à Sens l'extension Qlik Branch. Par cette extension, je défini une variable TypeAnneeSelect pour savoir si je veux traiter Annee ou AnneeSCO.
Dans mon graphique, j'ai en dimension :
= if ($(TypeAnneeSelect) = 1,
if (ANNEE_FH>0 and ANNEE_FH<2050 AND
aggr(Count(distinct ID_FAM_FH),ANNEE_FH) > 10
,ANNEE_FH )
,if (ANNEE_SCO_FH>0 and ANNEE_FH<2050 and
aggr(Count(distinct ID_FAM_FH),ANNEE_SCO_FH) > 10
,ANNEE_SCO_FH)
)
Selon que je sélectionne Annee ou AnneeSco dans mon extension, la dimension se met bien à jour.
En mesure j'ai
Count(distinct (ID_FAM_FH))
Et là, ça pose souci ...
Si je sélectionne Annee
2017 ==> 3
2018 ==> 2
Si je sélectionne AnneeSco
2017 ==> 3
2018 ==> 2
En gros il ne compte que quand Annee = AnneeSco.
Merci d'avance de votre aide.
Ce message a été modifié par : Nicolas Sinquin
- Tags:
- Group_Discussions
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Bonjour Christophe,
Je suis avec la version Sense Desktop, et je n'ai pas trouvé les composants qui m'allaient, d'où l'extension.
Sans quelques galères, j'ai commencé à tenter d'utiliser les set analysis.
en dimension j'en suis arrivé à
=aggr(only({$ <[NSN_FAMILLE_H.ANNEE_FH]= >} [NSN_FAMILLE_H.ANNEE_FH]), [NSN_FAMILLE_H.ANNEE_FH])
mais malheureusement ça ne répond pas complètement à mes besoins ... quand une année est sélectionnée, la sélection se fait également sur la dimension. Il me semblait que le <[NSN_FAMILLE_H.ANNEE_FH]= > gérait cela.
Sur les mesures j'ai abouti à ça :
=sum(aggr(Count({$ <[NSN_FAMILLE_H.ANNEE_FH]={'=count(distinct ID_FAM_ACT_FAM) >= 10'}>} [NSN_FAMILLE_H.ANNEE_FH]), [NSN_FAMILLE_H.ANNEE_FH])) qui semble correspondre.
Côté modélisation, si je met ces valeurs dans 1 seul champs, ça voudrait dire qu'il faut que je doublonne mes lignes ... Il s'agit en fait d'un champ calculé issu d'une date.
Merci.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Bonjour,
Pouvez vous expliquer à quoi sert toute cette partie dans votre dimension? Je pense que c'est de la que vient le problème.
if (ANNEE_FH>0 and ANNEE_FH<2050 AND
aggr(Count(distinct ID_FAM_FH),ANNEE_FH) > 10
,ANNEE_FH )
,if (ANNEE_SCO_FH>0 and ANNEE_FH<2050 and
aggr(Count(distinct ID_FAM_FH),ANNEE_SCO_FH) > 10
,ANNEE_SCO_FH)
)
Plusieurs choses me font tiquer; on évite en général autant que possible les dimensions calculées avec des if sur les valeurs de champs (pour des raisons de clarté et de performance).
J'ai également du mal à comprendre le test "aggr(Count(distinct ID_FAM_FH),ANNEE_FH) > 10".
La fonction aggr, par nature ne retourne pas un nombre mais un ensemble de valeur, et doit normalement être utilisée dans une autre fonction d’agrégation pour retourner une valeur numérique.
Enfin, (c'est peut être la cause du problème) pourquoi avoir dans le bloc sur l'année scolaire:
if (ANNEE_SCO_FH>0 and ANNEE_FH<2050
et pas
if (ANNEE_SCO_FH>0 and ANNEE_SCO_FH<2050
?
Martin
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Bonjour Martin,
Je suis débutant sur Qlik et je pense bien faire des erreurs de "débutant" ...
J'ai modifié la coquille sur le bloc, mais même résultat.
Je cherche à exclure les années :
à 0 et inférieures à 2050 (données aberrantes qui ne doivent pas être affichées dans ce graphique mais que je ne peux exclure du reste des analyses)
pour lesquelles j'ai une population minimale de 10 id
Nicolas
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Peux-tu mettre une copie d’écran de ton modèle de données ?
Ton script est un peu étrange
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Bonjour Sébastien,
voici le modèle. ID_FAM_FH a été renommé en ID_FAM_ACT_FAM.
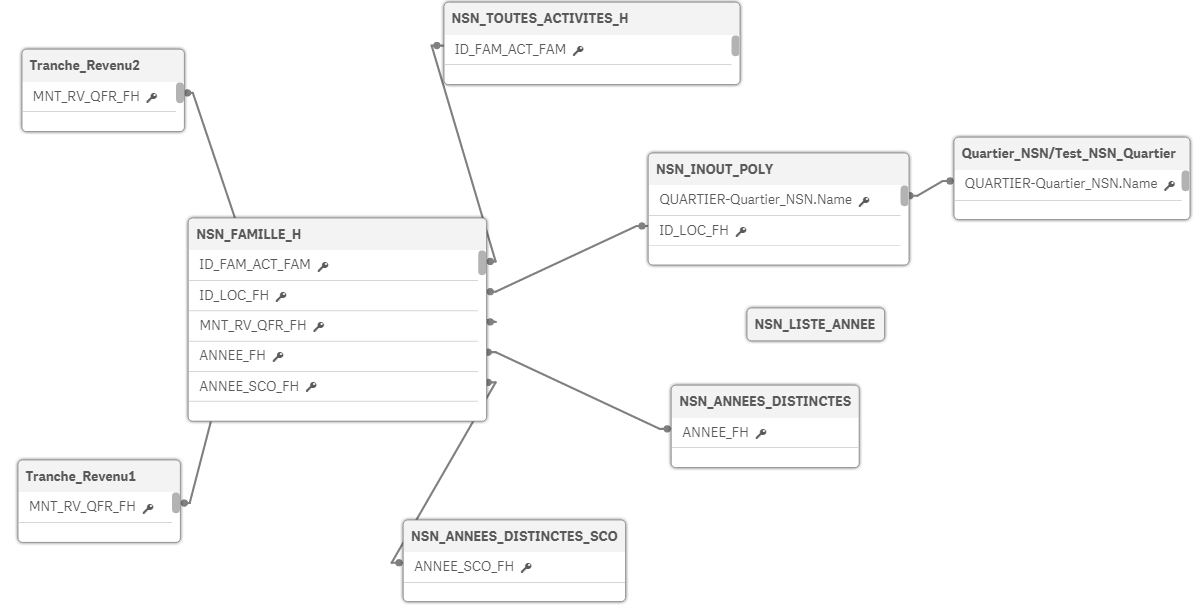
Si (comme) vous trouvez étrange ce que je fais, je veux bien quelques pistes 😉
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Bonjour,
Nicolas Sinquin a écrit:
Bonjour Martin,
Je suis débutant sur Qlik et je pense bien faire des erreurs de "débutant" ...
J'ai modifié la coquille sur le bloc, mais même résultat.
Je cherche à exclure les années :
à 0 et inférieures à 2050 (données aberrantes qui ne doivent pas être affichées dans ce graphique mais que je ne peux exclure du reste des analyses)
pour lesquelles j'ai une population minimale de 10 id
Nicolas
Si j'ai compris le besoin, tu fais pour moi deux erreurs :
Utiliser une extension là où des fonctionnalités standard te permettent de résoudre ton besoin
Vouloir filtrer ta dimension avec une expression complexe et non performante : utiliser des sets analysis dans la mesure (ci dessous) et mettre une limitation dans la dimension ( Valeur exacte >10)
Je te conseil la lecture de cet article :
https://www.quickintelligence.co.uk/qlik-sense-cycle-group/
Ensuite tu peux adapter ton set analysis :
(non testé dans un set analysis mais marche dans un TOTAL<[$(vDim)]>)
Tu peux faire : Count(DISTINCT {$< [$(vDim)] = {">0<2050"}>} ID_FAM_ACT_FAM)
Niveau modélisation, je me poserai la question de savoir si ces deux champs années doivent être séparé, ou^devenir le même champs avec un second champs d'attribut qui définit le "type d'année".
Bon courage !
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Bonjour Christophe,
Je suis avec la version Sense Desktop, et je n'ai pas trouvé les composants qui m'allaient, d'où l'extension.
Sans quelques galères, j'ai commencé à tenter d'utiliser les set analysis.
en dimension j'en suis arrivé à
=aggr(only({$ <[NSN_FAMILLE_H.ANNEE_FH]= >} [NSN_FAMILLE_H.ANNEE_FH]), [NSN_FAMILLE_H.ANNEE_FH])
mais malheureusement ça ne répond pas complètement à mes besoins ... quand une année est sélectionnée, la sélection se fait également sur la dimension. Il me semblait que le <[NSN_FAMILLE_H.ANNEE_FH]= > gérait cela.
Sur les mesures j'ai abouti à ça :
=sum(aggr(Count({$ <[NSN_FAMILLE_H.ANNEE_FH]={'=count(distinct ID_FAM_ACT_FAM) >= 10'}>} [NSN_FAMILLE_H.ANNEE_FH]), [NSN_FAMILLE_H.ANNEE_FH])) qui semble correspondre.
Côté modélisation, si je met ces valeurs dans 1 seul champs, ça voudrait dire qu'il faut que je doublonne mes lignes ... Il s'agit en fait d'un champ calculé issu d'une date.
Merci.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
La version desktop contient les même fonctionnalités que les versions serveurs, pour le script ou l'interface.
Aggr() n'est pas fait pour répondreà ton besoin à priori. Je maintiens que c'est ta modélisation qui ne dessert pas bien ton besoin métier.
Mais ça c'est compliqué à préconisé sans avoir une vue globale des données et du projet dsl...